数据集Infocom06记录了节点相遇情况,对其分析会发现节点i与节点j检测到对方的时间往往不一致,考虑到节点间通信需要同步,这样的话,求出节点间相遇的所有重叠区间,就可将有向图转化成无向图,便于后续分析(如社区检测)。本文先简单介绍数据集的格式,再结合源代码介绍求其重叠区间。
1. Infocom06格式
Haggle项目收集的数据集,格式很一致,通常包含若干文件。最有用的文件是contacts.Exp*.dat,描述设备间相遇情况,描述节点i从时间t1到时间t2遇到节点j,即前4列(node_i node_j start end),后面两列是基于前面4列组成文件计算得到的。详情见博文《Bubble Rap数据集Infocom05, Hong-Kong, Cambrige, Infocom06, Reality》。取部分行如下:
13 2 7261 7499 1 0
2 13 7289 7516 1 0
13 2 7866 8598 2 367
2 13 7997 9223 2 481
细心的你会发现,节点13检测到节点2的时间(7261)与节点2检测到节点13的时间不一样(7287),考虑到节点间通信需要同步,即只有在重叠区间方可通信(这样理解对吗?)。接下来介绍如何求出节点间所有的重叠区间。
2. 求重叠区间
我的方法有些笨,用Shell脚本和awk脚本。先用grep将节点对过滤出来,并用sort对开始时间(左区间)排序,最后用awk脚本求其重叠区间并输出。
2022-03-27更新:如果现在让我做,我会直接用Python来处理。
2.1 过滤节点对并排序
用grep命令将节点对保存在一个临时文件并排序,作为参数传给awk脚本,主要源代码如下:
devices=$(cat $contact_file | cut -f 1 | sort -n | uniq | wc -l)
for ((i=1; i<=devices; i++))
do
for ((j=i+1; j<=devices; j++))
do
#grep all the contact between node i and node j
grep "^$i $j " $tmp_duration_filter_file >> $tmp_duration_file
grep "^$j $i " $tmp_duration_filter_file >> $tmp_duration_file
sort -k3,3n $tmp_duration_file >> $tmp_overlapping_interval_file
#count overlapping interval between node i and node j
if [ -s $tmp_overlapping_interval_file ]
then
awk -f contact_duration.awk $tmp_overlapping_interval_file >> $sum_contact_duration_file
fi
done
done
注:本例grep的正则表达式是grep "^$i $j" ,这是因为我将datasets处理过了,即将时间间隔为0的行过滤掉并用空格作为输出分隔符。原数据集是用TAB作为分隔符,先按ctrl+v,再按TAB在vim输入TAB分隔符。
2.2 求重叠区间
经过上述的步骤,节点对的开始时间按递增排序,这里无须在乎节点的顺序(如1 3还是3 1)。两区间的重叠情况有如下3种(第二个区间的左区间总比第一个左区间要大,因为排序过):没有重叠、部分重叠、被包含。
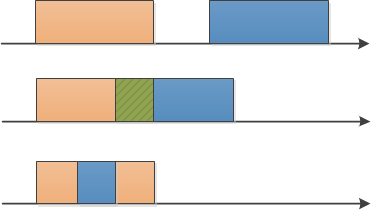
图1 重叠区间3种情况
awk脚本源代码如下,主要源代码已加粗:
function max(a, b)
{
return a>b?a:b
}
function min(a, b)
{
return a<b?a:b
}
BEGIN {
node_i = 0
node_j = 0
pre_start = 0
pre_end = 0
cur_start = 0
cur_end = 0
overlapping_start = 0
overlapping_end = 0
duration = 0
sum_contact = 0
sum_duration = 0
}
{
node_i = min($1, $2)
node_j = max($1, $2)
if (NR == 1) {
pre_start = $3
pre_end = $4
}
else
{
cur_start = $3;
cur_end = $4
if (cur_start > pre_end) #no overlapping
{
pre_start = cur_start
pre_end = cur_end
}
else if (cur_start <= pre_end) #overlapping
{
pre_start = max(pre_start, cur_start)
pre_end = max(pre_end, cur_end)
overlapping_start = max(pre_start, cur_start)
overlapping_end = min(pre_end, cur_end)
duration = overlapping_end - overlapping_start
sum_duration += duration
sum_contact++
}
}
}
END {
if (sum_contact!=0 && sum_duration!=0)
{
print node_i, node_j, sum_contact, sum_duration
}
}
3. 数据分析
上述中,还求出所有节点对总的相遇时间、总的相遇次数,有了这些,就可以对该数据集进一步分析,如Bubble Rap论文中的number of contacts、contacts duration分布图,社区检测(community detection)。我也做了同样的分析,但结果不是很理想。